Yazılım ve daha fazlası
“Söz uçar, yazı kalır.”
Twitter haritası - 2
Serinin bir önceki yazısında bahsettiğim Twitter arkadaş haritası uygulaması oldukça yavaş çalışıyor. Bu yazıda yavaşlığın sebebini bulacağım ve sonrasında da uygulamayı hızlandıracağım.
Problem
Twitter haritası - 1‘de geliştirdiğim uygulamada bir yavaşlık var. Yavaşlığın sebebi sunucu kaynaklı, bunun ispatını “chrome developer tools” ile veya hangi tarayıcıyı kullanıyorsanız onun geliştirici seçeneklerinden network hareketliliğini izleyerek yapabiliriz:
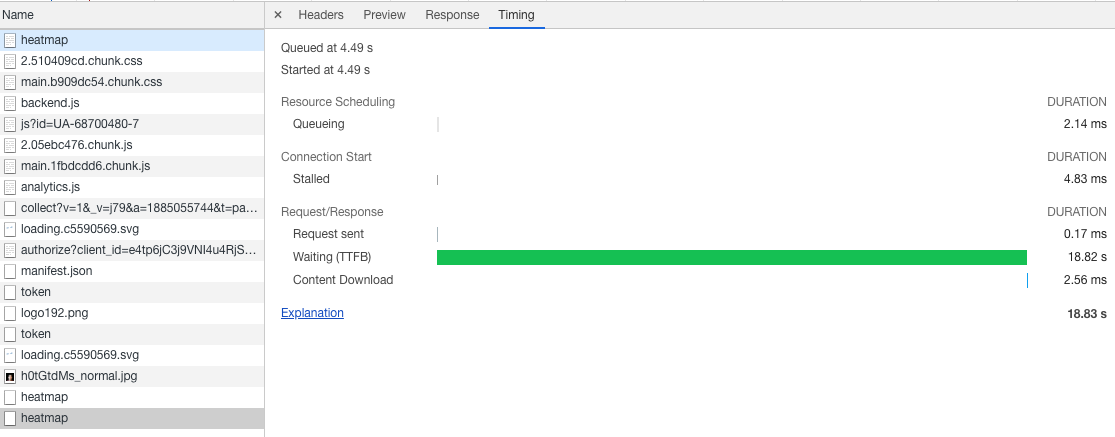
Gördüğünüz gibi, buradaki yavaşlık network’le alakalı değil. İsteğin gitmesi 0.17 milisaniye sürmüş, sunucu 18.82 saniye işlem yapmış ve hazırladığı cevabı istemciye göndermesi 2.56 milisaniye sürmüş. Bu deneyi yaparken, istemci de sunucu da kendi bilgisayarımdaydı, o yüzden network ihtimalini tamamen aradan çıkarmış oldum aslında. Zaten 18.82 saniyelik bekleme süresinden de anlayacağımız üzere, sunucu bir yerlerde takılıyor.
Bir uygulama veya yazılımın kalitesini artıran en önemli özellik, bir problem olduğunda kolayca fark edip problemin kökenine hızlıca inebilmemizi sağlayan kritik ölçümler barındırmasıdır. Buna ingilizcede observability deniyor, gözlenebilirlik olarak çevirilebilir. Mesela benim twitter uygulamam için konuşursak, sunucu tarafındaki yavaşlığın sebebini bana sayılarla ispatlayacak birkaç performans göstergesi olsaydı sorunun kökenine hemen inebilirdim. Şu haliyle bir yavaşlık olduğunu biliyorum ama yavaşlığın sebebini bilmiyorum. İlk aklıma gelen ihtimaller şunlar:
- Auth0 API metodları geç cevap dönüyor
- Twitter API metodu geç cevap dönüyor
- Lokasyon bilgilerini koordinata çevirdiğim kod parçacığı yavaş çalışıyor
Ölçüm
İlk iş, uygulamadaki entegrasyon noktalarında tek tek gecikme sürelerini kaydetmek. Bunun için, asıl işin yapıldığı yer olan aşağıdaki kod parçacığını, minimum değişiklikle nasıl kolayca ölçülebilir hale getiririm diye düşündüm:
return fetch(process.env.AUTH0_TOKEN_URL, options)
.then(res => res.json())
.then(res => {
return fetch(process.env.AUTH0_ADMIN_GET_USER_URL + auth0Id, {
method: "GET",
headers: {
authorization: "Bearer " + res.access_token
},
});
})
.then(res => res.json())
.then(getFriends)
.then(maps.getCoordinates);
Buradaki kriterim, mevcut Promise yapısını fazla bozmamak ve okunabilirliği en az bunun kadar iyi olacak şekilde düzenlemek. Yani örnek vermek gerekirse,
.then(getFriends)
olan kısım
then(metod_ismi("TwitterPerformansi", getFriends))
şeklinde yazılabilsin.
Burada metod_ismi, parametre olarak bir ölçüt alacak (“TwitterPerformansi” gibi) ve bir de yapılacak olan işi alacak.
Metod bir Promise dönmek zorunda ki .then‘lerle promise zincirini oluşturmaya devam edebilelim.
Buraya kadar metodun imzasından bahsetmiş olduk, yani hangi parametreleri alıp değer olarak ne dönecek. Biraz da metodun implementasyonu üzerine kafa yoralım. Aslında istediğimiz şey basit: ikinci parametre olarak aldığımız işi yapmadan önce saate bak, yaptıktan sonra saate bak ve ikisi arasındaki süreyi hesapla. İlk parametreyle de farklı ölçümleri birbirinden ayırmış olacağız.
measureFunction ismi vereceğimiz metodumuz şöyle olacak:
const { PerformanceObserver, performance } = require('perf_hooks');
const events = [];
function measureFunction(label, promise) {
let begin;
return (response) => {
return new Promise(function(resolve, reject) {
begin = performance.now();
resolve(response);
})
.then(promise)
.then(res => {
events.push({label: label, duration: performance.now() - begin});
return res;
});
};
}
İki parametre alıyor, label ve promise. Metod, değer olarak başka bir function expression dönüyor, yani döndüğü değer çağrılabilen bir fonksiyon. Biraz karışık gelebilir ama, kısaca söylemek gerekirse fonksiyonumuz başka bir fonksiyon dönüyor. Döndüğü fonksiyona odaklanacak olursak, bir Promise döndüğünü göreceksiniz. Bu Promise, resolve ederken sırasıyla
- başlangıç zamanını kaydediyor
- parametre olarak aldığımız ve asıl işi temsil eden (mesela twitter API’sini çağırmak gibi) promise’i zincire ekliyor
- asıl iş bitince (promise resolve edince) bitiş zamanını kaydediyor.
- başlangıç ve bitiş arasında geçen zamanı hesaplayıp modül seviyesindeki events değişkenine ekliyor.
AWS CloudWatch
Topladığım ölçümleri, AWS’nin CloudWatch hizmetini kullanarak saklayacağım.
CloudWatch hizmeti, hem uygulama logları hem de uygulama performansını izlemek için kullanılabiliyor.
CloudWatch’la hazır gelen bazı performans göstergeleri var, bunlardan biri lambda metodunun çalışma süresi (yani metodun başlangıcından bitişine kadar geçen süre).
Yukarıda sunucunun yavaşlığını kendi açımdan ölçmüştüm, bu yavaşlığı AWS üzerinde de görebilirdim:
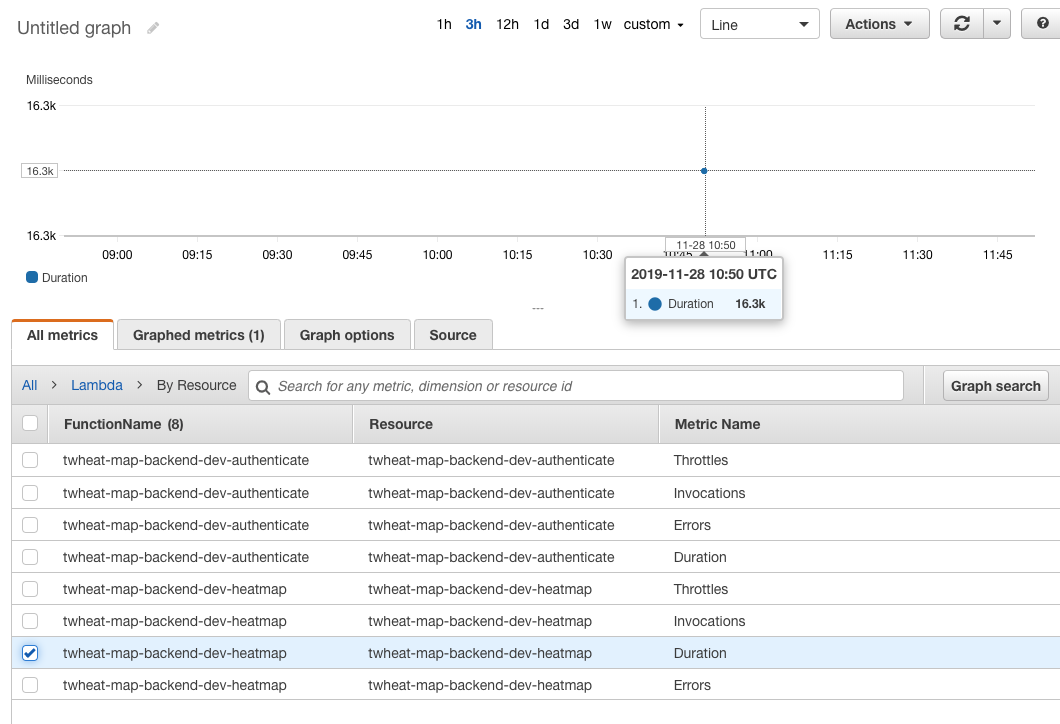
Burada görüyorum ki lambda 16.3 saniye sürmüş, bu süre geçerken istemci beklemiş de beklemiş. Web uygulamalarında 2-3 saniyeden fazla bir gecikme, çok da kabul edilebilir değil.
Ne yapacağımıza karar verdiğimize göre, entegrasyon için kod yazmaya hazırız. AWS’nin servislerine kolayca entegre olabilelim diye farklı diller için SDK’ları bulunmakta. Benim sunucum nodejs ile yazıldığından, gidip nodejs SDK’sını kurdum:
yarn add aws-sdk
Daha sonra SDK’yı kullanmak için, const AWS = require('aws-sdk'); diyerek SDK objesini oluşturuyoruz.
Bize CloudWatch gerektiği için, const cloudwatch = new AWS.CloudWatch(); ile CloudWatch objesini alıyoruz.
İlgilendiğimiz metod, putMetricData.
Bu metod SDK metodu, arka tarafta SDK gidip asıl PutMetricData REST API endpoint’ini çağırıyor.
Bu metodu çağırabilmek için gerekli olan IAM izni cloudwatch:PutMetricData ile sağlanıyor.
AWS’nin bütün metodları bir IAM izni gerektiriyor, metodu çağıran uygulamanın gerekli izni yoksa hata alacaktır.
Şimdi ilgili metodu çağıran kod parçacığına bakalım:
const { PerformanceObserver, performance } = require('perf_hooks');
const AWS = require('aws-sdk');
const cloudwatch = new AWS.CloudWatch();
function reportLatencies(response) {
const params = {
MetricData: events.map(e => ({
MetricName: e.label + "Latency",
Unit: "Milliseconds",
Value: e.duration
})),
Namespace: process.env.CLOUDWATCH_NAMESPACE
};
return cloudwatch.putMetricData(params).promise()
.catch(err => {
console.log("Error while calling CloudWatch API: " + err + "\nParameters were: " + JSON.stringify(params));
})
.then(() => {
events.length = 0; // event'leri bosaltalim ki bir sonraki cagrida gelmesinler
return response;
});
}
Metodun yaptığı şey basit, response adında bir parametre alıyor ve buna hiç dokunmuyor. Önce CloudWatch putMetricData metodunu çağıran, daha sonra hata olursa bunu sessizce loglayan ve son olarak da aldığı parametreyi aynen veren bir Promise dönüyor. Buradaki önemli nokta catch ifadesi. Entegrasyon noktalarında hata yönetimi çok önemlidir. Mesela çağırdığınız bir servis hata alabilir, bu durumda üç temel seçeneğiniz var:
- tekrar denemek
- hatayı görmezden gelip devam etmek
- hatayı yukarıya iletmek (yani handle etmemek diyebiliriz, çaresine beni çağıran baksın)
CloudWatch, uygulamamızın işlevselliği için kritik değil, sadece performans ölçebilmek için kullanıyoruz. Bu durumda, CloudWatch servisinin aldığı hata çok umrumda değil. Bu yüzden catch içerisinde sadece logluyorum ve yoluma devam ediyorum. IAM yetkisini vermeden bu metodu çağırmaya çalıştığımda, hatanın loglandığını fakat uygulamanın da beklendiği şekilde çalıştığını doğruladım. Gelen hata mesajı şuydu:
Error while calling CloudWatch API: SignatureDoesNotMatch: The request signature we calculated does not match the signature you provided. Check your AWS Secret Access Key and signing method. Consult the service documentation for details.
CloudWatch API metodunu çağıran birim heatmap lambda metodumuz. Yetkiyi bu metoda atayacağız, bunun için serverless.yml dosyamızda provider altına yeni bir bölüm ekliyoruz:
iamRoleStatements:
- Effect: "Allow"
Action:
- cloudwatch:PutMetricData
Resource: "*"
Bu sayede, serverless uygulamamızdaki tüm metodlar cloudwatch:PutMetricData yetkisine sahip olacak. Aslında bu yetkiyi sadece heatmap lambda metoduna verebilirdik fakat biraz üşengeçlikten, metod metod ayırmadım yetkileri. Bu haliyle, API Gateway authorization işini gören lambda metodumuzun da ilgili CloudWatch metodunu çağırmaya yetkisi var. İdeal olan, tüm metodlara ihtiyaç duyulan minimum yetkiyi vermek, mesela authorization lambda’sının CloudWatch’la bir işi yok, o yüzden vermesek daha iyi olurdu. AWS dokümanlarında bu konuyla ilgili detaylı bilgiyi bulabilirsiniz, bu prensibin adı least privilege.
Ölçüm Sonuçları
Sunucunun yeni halini AWS’ye deploy ettikten sonra, uygulamayı kullandım ve performans göstergelerine CloudWatch’tan baktım:
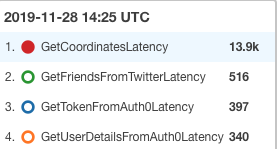
Görüldüğü gibi, lambda metodumuzun en çok zaman alan kısmı lokasyonları koordinatlara çevirdiğimiz kısım. Auth0 için ayrı ayrı yaklaşık 300 milisaniye zaman harcamışız, Twitter için 500 milisaniye ve koordinatlara çevirdiğimiz kısımda ise neredeyse 14 saniye zaman harcamışız. Şimdi bu metodun detaylarına bakalım:
function getCoordinates(locations) {
return locations
.map(l => stringSimilarity.findBestMatch(l, citiesArray).bestMatch.target)
.map(l => coordinatesMap.get(l));
}
Bu fonksiyon parametre olarak bir array alıyor. Array’in elemanları birer string ve içerisinde lokasyon bilgisi bulunuyor. Her eleman için gidip string-similarity kütüphanesinin findBestMatch metodunu çağırıyoruz. findBestMatch metoduna parametre olarak ilgili eleman (lokasyon string’i) ve bir de bütün ihtimallerin olduğu (yaklaşık 13000 adet lokasyon) diğer array’i veriyoruz.
Bu algoritmayı hızlandırmak için ilk aklıma gelen şey, lokasyonların olduğu array’in içerisinden mükerrer lokasyonları çıkarmak. Düşünsenize, arkadaş listenizde aynı yerde bulunan pek çok insan vardır. Mesela benim yaklaşık 250 kişilik arkadaş lokasyonu listemin 100 tanesi mükerrer kayıt. Kodu aşağıdaki şekilde güncelledim ve string-similarity kütüphanesinden dönen sonuçları geçici olarak cache’lemiş oldum ve aynı lokasyon için bir daha kütüphaneyi çağırmamış oldum:
function getCoordinates(locations) {
let locationMap = new Map();
return locations
.map(l => {
if (locationMap.has(l)) {
return locationMap.get(l);
} else {
let location = stringSimilarity.findBestMatch(l, citiesArray).bestMatch.target;
locationMap.set(l, location);
return location;
}
})
.map(l => coordinatesMap.get(l));
}
İkinci bir iyileştirme olarak da, üç ayrı map hazırlayacağım. Data set‘imizdeki veriler şu formatta:
{
"city": "Los Gatos",
"lat": 37.2307,
"lng": -121.9563,
"country": "United States",
"iso2": "US",
"admin_name": "California"
}
“city”, “country” ve “admin_name” için üç ayrı map hazırlayacağım:
const worldCities = require('./worldcities.json');
const cityMap = new Map();
const countryMap = new Map();
const adminMap = new Map();
const coordinatesMap = new Map();
function getWorldCityIdentifier(worldCity) {
return worldCity.city + ", " + worldCity.iso2 + ", " + worldCity.country;
}
function addToMap(map, key, worldCityIdentifier) {
if (map.has(key)) {
map.get(key).push(worldCityIdentifier);
} else {
map.set(key, [worldCityIdentifier]);
}
}
for (let i = 0; i < worldCities.length; i++) {
let worldCity = worldCities[i];
let worldCityIdentifier = getWorldCityIdentifier(worldCity);
addToMap(cityMap, worldCity.city, worldCityIdentifier);
addToMap(countryMap, worldCity.country, worldCityIdentifier);
addToMap(adminMap, worldCity.admin_name, worldCityIdentifier);
coordinatesMap.set(worldCityIdentifier, { lat: worldCity.lat, lng: worldCity.lng });
}
“coordinatesMap” yine olacak çünkü en son lokasyon bilgisini bu map’ten alacağım. Algoritma şu şekilde çalışacak, ilk iyileştirme olan cache‘imizde aradığımız lokasyon yoksa kullanıcının lokasyonunu virgülden ayırıp birden fazla kelime haline getireceğiz. Her bir kelime için gidip üç map’e de bakacağız, eğer herhangi bir map’te bu kayıt varsa ona ait yer array‘inde en yakın lokasyon hangisi bulmak için string-similarity kütüphanesini çağıracağız. Tüm map’leri gezdikten sonra, en yakın benzerlik değerine sahip sonucu kullanarak coordinatesMap’ten ilgili koordinatları döneceğiz. Eğer hiçbir map’te hiçbir kelime bulunamazsa, bu durumda data set‘imizdeki şehirlerin bulunduğu bir array üzerinde yeniden string-similarity işlemini yapıp sonucu kullanacağız. Dikkat ettiyseniz algoritmamızda sonuç bulamama durumu yok, tam eşleşmese de bir sonuç dönecek. Elbette bu şekilde algoritmanın doğruluk yüzdesi biraz azalmış oldu ama kendi hesabımda yaptığım denemede gayet başarılı buldum sonuçları:
Algoritmanın doğruluğundan memnun olduğuma göre, sırada algoritmanın performansını görmek var. Bunun için yeni kodu AWS’ye deploy ettim ve uygulama üzerinden Twitter arkadaş haritamı görmek için Map linkine tıkladım. Daha sonra AWS CloudWatch konsolundan GetCoordinatesLatency metriğine baktım:
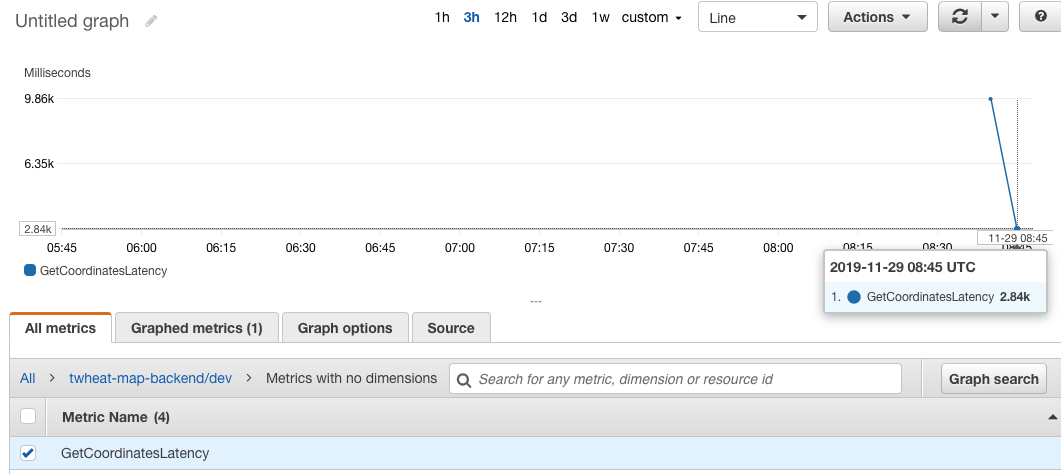
Gördüğünüz gibi, önceden yaklaşık 14 saniye süren bu işlem ilk iyileştirme sonucu 10 saniyeye düşmüş ve ikinci iyileştirmeyle birlikte 3 saniyeye kadar inmiş. Henüz 10000’ler seviyesinde arkadaşı olan bir hesaptan ne kadar performanslı geldiğine bakmadım. Muhtemelen kabul edilemeyecek seviyede yavaş çalışacaktır ama yine de şimdilik 14 saniyelerden 3 saniyeye çekmiş oldum performansı. Aslında 13000 adet lokasyon barındıran bir data set gereksiz kalabalık, bir sonraki iyileştirme olarak bu data seti 1000 veya en fazla 2000 lokasyona indirmeyi düşünüyorum. Data set’e bakarsanız, lüzumsuz bir çok yer barındırıyor, mesela:
{
"city": "Longyearbyen",
"lat": 78.2167,
"lng": 15.6333,
"country": "Svalbard",
"iso2": "XR",
"admin_name": ""
}
78. kuzey paralelinde yer alıyormuş, az ötesi kuzey kutbu :smile:
Şimdilik bu kadar, muhtemelen serinin bir sonraki yazısında AWS’nin managed (AWS tarafından yönetiliyor, her şey hazır) NoSQL veritabanı olan DynamoDB’yi uygulamaya entegre edip, Twitter’dan gelen cevapları belirli bir süre cache’leyeceğim. Bunun faydası hem Twitter API’ını çağırıp vakit kaybını önleyecek, hem de Twitter ücretsiz plan’da API metodları için bazı limitler koymuş durumda. Hobi uygulamam için Twitter’a para ödemeyi düşünmüyorum. O yüzden, API metodlarını ne kadar az çağırırsam o kadar iyi.
Sunucu tarafındaki projeye CI/CD süreci eklediğim yazı için tıklayın.